What We Built
Our system listens to your voice, understands your intent, and generates a 3D mesh that can be sent directly to a 3D printer. The pipeline combines three major components:
Speech-to-Text: Using OpenAI’s Whisper model, our system transcribes spoken language into textual prompts with high accuracy (~95–98.5%).
Text-to-Image Generation: We condition a Stable Diffusion model on the generated text to create multi-view images of the described object—providing visual perspectives necessary for reliable 3D reconstruction.
Image-to-3D Mesh Generation: Finally, using the InstantMesh framework (a sparse-view reconstruction model based on LRM), the system builds a printable 3D mesh from the multi-view images. The result is a watertight, printable object ready for real-world use.
Experimental Pipeline
Approach 1: Point-E + Point2Mesh
Converts speech to point clouds via OpenAI’s Point-E model.
Uses Point2Mesh, a GCN-based self-prior method, to deform an initial mesh to match the point cloud.
Resulted in coarse meshes, good for simple shapes but lacked finer surface detail.
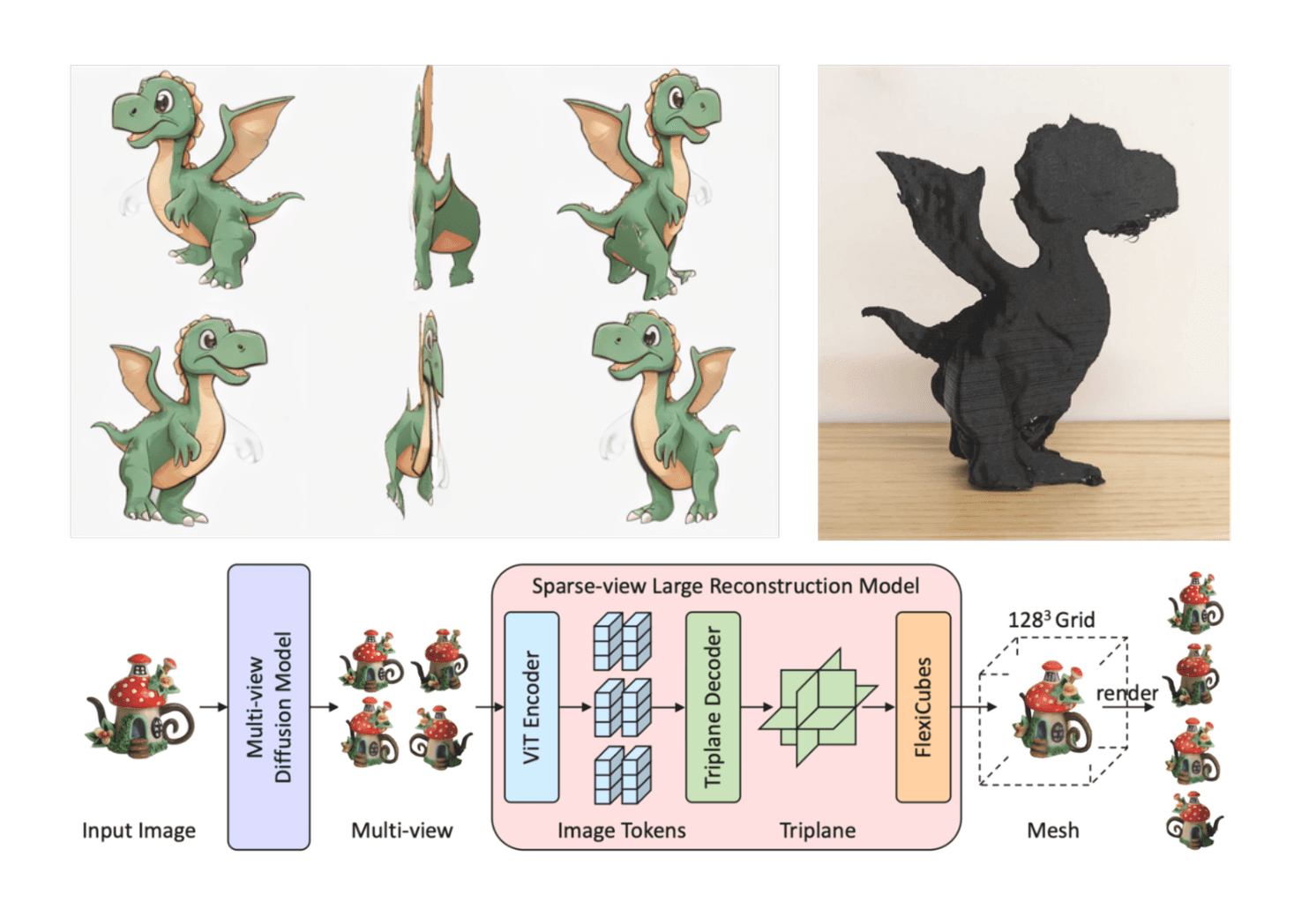
Approach 2: Stable Diffusion + InstantMesh
Converts text to multi-view images using a diffusion model.
Feeds images into InstantMesh to reconstruct high-fidelity meshes.
Performed significantly better in mesh quality, especially for intricate details like cups, handles, and cartoon characters.
Examples
Cartoon Dinosaur: Accurately captured complex silhouette and textures.
Cup with Elephant Handle: Maintained key features like handle curvature and depth—though inner geometry remains a challenge.
Sketch Inputs: Some difficulty capturing depth from 2D drawings, highlighting the need for more robust geometry inference.
Challenges & Limitations
Depth Estimation: Flat meshes when sketch-based inputs are used due to loss of volumetric understanding.
Mesh Fidelity: Lower resolution meshes from Point-E lacked detail; diffusion-based methods fared better.
Multi-view Consistency: Artifacts and misalignments in some diffusion-generated perspectives affect mesh coherence.
Thin Structures: InstantMesh struggles with fine details like thin handles or wings.
Future Directions
Higher Resolution Meshes - Incorporating architectures that generate higher-than-64x64 triplanes to boost surface detail.
Better Multi-View Coherence - Using multi-view consistent diffusion models to reduce inconsistencies between generated views.
Alternative Extraction Models - Exploring FlexiCubes alternatives and differentiable surface extraction to better preserve geometry.
Interactive Feedback - Adding UI/voice feedback loops to allow users to iteratively refine their design by speaking adjustments.
Made with ❤️ by:
Trushant Adeshara
Saket Pradhan
Kajal Awasthi
Pannaga Sudarshana